The Inner Product,
October 2003
Jonathan Blow (jon@number-none.com)
Last updated 12 January 2004
Adaptive Compression
Across Unreliable Networks
Related articles:
Arithmetic Coding, Part 1 (August 2003)
Arithmetic Coding, Part 2 (September 2003)
Piecewise Linear Data Models (November 2003)
Packing Integers (May 2002)
Scalar Quantization (June 2002)
Transmitting Vectors (July 2002)
In a networked game system, we want compress our network messages to reduce bandwidth usage. Last month we compressed our output using an arithmetic coder with a static data model. The data model consisted of some statistics we generated by analyzing training data; the arithmetic coder then used those statistics to compress transmitted data.
This approach offers limited effectiveness. Often, our network messages will have characteristics significantly different from the training data; in these cases, compression will be poor. File-based arithmetic coders deal with this problem using adaptive compression: as data is processed, they modify the statistics to conform. Successful adaptive compression depends on the decoder's ability to exactly duplicate the changes enacted by the encoder.
Unfortunately, in high-performance networked games, we want to send most of our data in an unreliable manner (for example, using UDP datagrams). Because of this, the straightforward implementation of adaptive compression won't work. The server would base its statistics on messages transmitted, and the client would base its statistics on messages received. As soon as a single message is lost on the network, the client falls out of step with the server; the client is now permanently missing data needed to reproduce the statistics, so everything he attempts to decode in the future will be garbage.
One Possible Solution
We might solve this problem by making the server authoritative over the current data model. That is, both client and server start with the same statistics. As the server sends data to the client, he measures its statistics, but doesn't yet incorporate them into the data model he's using for transmission. Every once in a while, the server gathers together all the statistics from recent messages and builds a new data model, which he transmits to the client. As soon as the client acknowledges receipt of the new model, both client and server switch to this model for future transmissions.
This will work, but the fact that we need to transmit the statistics is a major drawback. One of the most attractive aspects of adaptive compression, in the domain of files, is that the statistics are implicit and thus take up no space in the compressed output. It's a shame to give that up; if we do, suddenly adaptive compression becomes a questionable pursuit. For adaptive compression to be useful, we need to save a lot more bandwidth (through adaptation) than we spend (by transmitting the statistics). But generally, the more effective statistics will be, the more space they require. So really, we'd prefer a solution that allows the statistics to remain implicit.
An Efficient Solution
Despite packet loss, there is enough shared knowledge between the client and the server to enable adaptive compression with implicit statistics. I'll start with a straightforward yet cumbersome method of accomplishing this; then I'll refine the method.
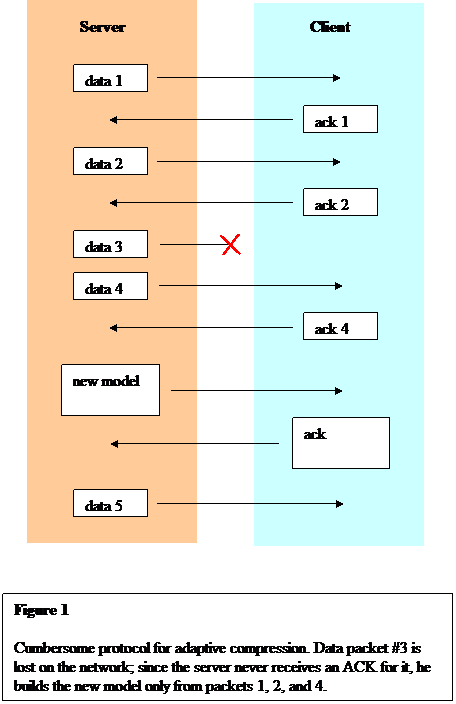
Though the server can't predict which packets will actually reach the client, the client can tell him this information after the fact. Suppose the client acknowledges each message he receives; the server then uses these acknowledgements to build a new data model. This new data model uses only statistics from messages the client received. The server must then tell the client when to start using the new model, and which messages were used to build that model, because the client doesn't know which ACKs the server received (ACKs can be lost too!). In a naive implementation, the server and client need to stop and synchronize when switching the data model, because the server needs to make sure the client knows the correct statistics before continuing with new packets. Figure 1 illustrates this protocol.
|
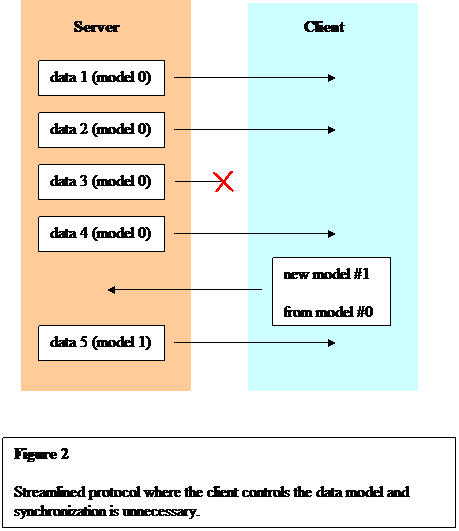
So far there's a lot of round-tripping and some annoying synchronization. Fortunately, all that can be eliminated. First we perform a conceptual refactoring and make the client (or more generally, the message receiver) authoritative over the data model. Because the receiver knows which messages were not lost, he's in the best position to choose the model. Instead of ACKing packets individually, the client just tells the server, "Build a new data model, based on the old one, but including also the statistics of messages 0, 1, ... and 9". So far this "build a new data model message" is nothing fancy, essentially just a big batched set of acknowledgements; in a moment, though, we'll make it a little more powerful.
This request for a new table might be lost or delayed, and we don't want to synchronize on such an event. So we enable the server and client to keep track of some small number of old data models; in the sample code, I arbitrarily chose 7. Each packet is labeled with the index of the data model that was used to encode it. So suppose the client and server are both using model 3, and the client sends the request "build model 4, starting with model 3 and mixing in this list of messages". If the request succeeds, the server starts sending packets labeled as model 4, and the client knows how to decode that (because the client built model #4 for himself at the same time he told the server to build model #4). If the request is lost on the network, the server's packets will continue to be labeled 3. Because the client still remembers table #3, he can decode these successfully. All this is illustrated in Figure 2.
 |
This data model index is prefixed to each packet, so it requires a little bit of extra bandwidth, perhaps 3 bits. So that packets can be ACKed, we need to give them unique identifiers, which takes some more bandwidth. These amounts are small, though, compared to the savings we ought to get from compression. Bandwidth overhead is not a problem with this algorithm.
It's with memory that we may see a problem.
Reducing Memory Usage
Because the server doesn't know in advance which messages will be used to generate a new table, he needs to remember statistics for each individual message he sends. The memory usage is not so bad if you are just thinking about transmitting to one client. But if you are making an MMO game with 1000 clients logged into the same server, suddenly we're talking about some serious overhead. Exactly how much overhead depends on the data model, but keep in mind that data models can be quite large. The simple order-1 model from last month will often be tens of kilobyes, and you want to use something more sophisticated than that! Though fortunately, incremental data model storage techniques may help you keep these sizes under control.
On the other hand, instead of storing a large high-order probability table for each message, the server could just store the messages themselves. When a request comes in to build a new model, the server can generate the statistics for each message by decoding them just as the client would. That adds to our CPU cost, though, since the server is eventually decoding just about every message it encodes. Decoding tends to be more expensive than encoding, so we will have more than doubled our CPU cost. The extra cost isn't expensive enough to worry about for a single stream, but in a system with 1000 clients, the cost may be prohibitive.
But even storing messages like this, our memory usage may still be uncomfortably large. If we're transmitting 1 kilobyte per second to each client, and we update a client's data model every 60 seconds, we need at least 60 kilobytes per client; times 1000 clients, that's 60 megabytes, which isn't funny. That minimum figure assumes no packet loss among any clients, which is unrealistic; besides, we still must pay the hefty CPU cost to decode all that. Cleary, we'd like a more attractive solution.
My approach is to group messages into batches, say, 10 messages per batch. The server remembers one data model per batch, and the client requests new models by specifying the batch numbers. (The batch number for each message is just its sequence number divided by 10, rounded downward to yield an integer).
This batching degrades the performance of the compressor slightly in the event of packet loss. If the client fails to receive some message from a batch, then none of the other messages in that batch can be used in any new data model (because the server has mixed the statistics from those messages all together and can't separate them again). Because of this the effect of packet loss is magnified. For a batch size of 10, 1% packet loss means 10% of batches are lost; 5% packet loss means 40% of batches are lost; 10% packet loss means 65% of batches are lost. These numbers sound high, but they're really not so bad. If the packet loss gets higher than 5%, the game is likely to feel unplayable anyway (due to general poor connection quality), so we're really only worried about losses below that rate. But as it happens, the adaptive modeler performs surprisingly well even with 10% packet loss. Apparently, we can still do a reasonable job of tracking message statistics even without seeing the majority of the messages. Table 1 shows the resulting compression rates for the sample code at varying rates of packet loss.
|
Table 1 Uncompressed data size 296,906, 10 messages per batch, 500 bytes per message. The line for 100% packet loss tells you how effective the static data model would be on its own.
|
|
Packet Loss |
Compressed Size (bytes) |
Compression Achieved |
|
0% |
148,209 |
50.1% |
|
1% |
149,863 |
49.5% |
|
5% |
154,407 |
48.0% |
|
10% |
159,352 |
46.3% |
|
100% |
185,890 |
37.4% |
Forgetting Message Statistics
Once the server uses a batch of statistics to build a new data model, he can forget those statistics and free up memory. But to cope with packet loss, and to prevent denial-of-service attacks, the server will need to discard unused statistics when they become old enough. This raises the possibility that the client will request a new model using batches the server has thrown away. That's not a big deal; the protocol handles it just fine. When the server finds that he no longer knows the statistics for one of the batches, he just ignores the request. The server continues onward, using the old data model for transmission. The result is the same as if the client's request were lost on the network.
The Sample Code
The results in Table 1 were measured from this month's sample code. The code performs a simple simulation of a client/server system. To keep the code focused, data is not actually transmitted over a network. Instead, the program's main loop passes messages between objects representing the client and the server, with a random chance for each message to be destroyed instead of relayed.
Like last month, the code uses training data to build an initial data model. But this time, that model is used only as a starting point. Afterward, the data model is updated at the client's request. Because both client and server compute the same data models for each message batch, the data models stay in sync.
The server transmits a 300k stream to the client; this stream consists of the first two books of Paradise Lost, followed by the comp.graphics.algorithms FAQ, followed by some interesting C++ code. As you can see from Table 1, we achieve roughly 50% compression, which is pretty good!
Adjustable settings are provided for you to control packet loss, maximum message size, batch size, and the weight new message statistics are given when mixed with old ones; you can play with these values and see how the results change.
As already mentioned, this compression algorithm requires unique identifiers (like sequence numbers) on all unreliable packets. Nicely, in addition to allowing compression, these sequence numbers can be put to other uses. For instance, we can use them on the client to estimate the current server-to-client packet loss; that estimate can be very useful in dynamically adjusting the behavior of the network protocol to maximize performance. The sample code measures the approximate packet loss and prints it out for you after the test is done.
Future Work
The sample only allocates a fixed range for sequence numbers; if you try to send too long of a message, the sequence numbers will overflow, and the protocol will malfunction. For a real game you will want to change this. It's not hard to handle; you just need the client and server to understand that sequence numbers will, at some point, wrap back around to 0. However, I wanted the sample code to be minimal and clear, so I left this out.
Currently, the client and server only use one data model at a time. Though they remember a history of several models to avoid synchronization, only the most recent is used by the server to encode outgoing data. We might improve compression efficiency, at a large CPU cost, by having the server attempt to encode each outgoing packet using all of the consensual data models, transmitting the version that came out the smallest. I leave this as an exercise to the interested reader, since the CPU cost on current hardware would make this approach unattractive to many people.