The Inner Product, January 2004
Jonathan Blow (jon@number-none.com)
Last updated 3 April 2004
Designing the
Programming Language
"Lerp", Part 1
Related articles:
Predicate Logic (December 2003)
Lerp 2 (February 2004)
Lerp 3 (March 2004)
During the autumn of 1994 I attended a small conference in
New Mexico called the USENIX Symposium on Very High Level Languages. I was in
college at the time, and a member of the contingent who thought "very high
level" meant features like closures and continuations. The conference, on the
other hand, had been organized by folks who thought "very high level" meant
"helps you get a lot of work done quickly".
Among many things that happened that weekend, I had a
conversation with Larry Wall, the creator of the programming language perl,
which had already proven quite popular at that time. During this discussion I
suggested that perl was icky because it wasn't very "orthogonal".
In the sense that language designers use the word,
orthogonality means that there is no redundancy in the language's feature set:
there's only one fundamental way to accomplish any particular kind of task, so
that (ideally) you achieve the maximum amount of expressive power with the
minimal amount of language complexity. In the academic world, orthogonality is
one of the main sources of beauty in language design.
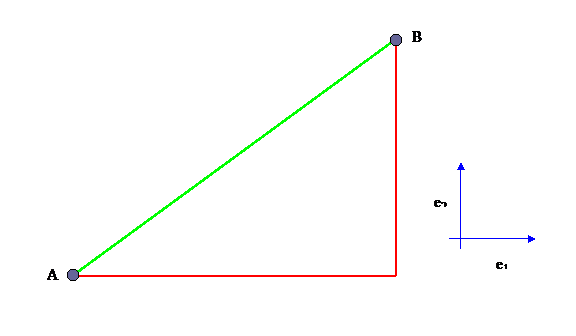
Larry took the position that orthogonality isn't actually a
good idea. He used the analogy that, if you want to travel from point A to
point B, then you have to travel further if you can only move along the
orthogonal grid lines (you must travel the Manhattan distance); what you really
want to do is move directly along the diagonal line between A and B (and you
must only travel the L2 distance). See Figure 1.
Back then, I regarded this diagonality analogy as somewhat
ill-formed, an over-zealous application of the term "orthogonal". But now,
years of real-world experience later, I see that Larry is right. Also, I am now
more comfortable with mathematics, and I no longer think of the "orthogonality"
idea as an ill-fitting metaphor. Rather, I think it's a fairly accurate
description, perhaps even an isomorphism rather than an analogy.
Nowadays you can find references on the web to Larry's
philosophy, that he has designed perl to be "a diagonal language" (see For More
Information).
Perl's doing something right
If you're fluent in perl and you're working on a problem in
perl's domain (string and file processing), perl offers a huge productivity
boost above other languages. At least part of the reason for this effectiveness
is the diagonality principle. It's not the only reason -- something can be
attributed to the language's general high-levelness and the availability of many
utility functions; also, when programming in perl, one tends to adopt an
attitude that software engineering and meditating on structure are not so
important for the task at hand, and this allows one to progress quickly toward a
solution unfettered by those design concerns. Though this latter effect is
separate from the diagonality principle, I think diagonality encourages it.
Last month I discussed some of the frustrations we face
with regard to software development. As a thrust toward some kind of solution,
I've decided to make a new language, adopting perl's diagonality principle but
taking it in a different direction. Whereas perl had its origins in the system
administration world, I want this new language to be tooled for writing gameplay
code, scripted events, and other manipulations
of objects in a world.
I'm whimsically naming my new language "lerp" for two
reasons: it's a
permutation of the letters in "perl", and lerp is the
common abbreviation for "linearly interpolate"; going back to our
get-from-A-to-B-on-a-grid example, lerping from A to B gives you the
shortest-line path (assuming, ahem, that the space is linear).
Basic design of Lerp
Lerp is a fusion between the imperative style of a language
like C, and the declarative style of a language like Prolog. When I read
introductory books about Prolog (see For More Information), I am always struck
by how simple, intuitive, and powerful the language seems, as long as I am still
in the early chapters of the book. But before long, around chapter 3 or 4,
Prolog suddenly gets nasty. The reason is the orthogonality principle -- Prolog
has some cool ideas about pattern matching, but then the language designer had
to go and build an entire Turing-complete language out of those few ideas.
"When all you've got is a hammer, everything looks like a nail." The early
intuitiveness of Prolog quickly falls prey to the weird quasi-declarative
semantics required to accomplish imperative-style tasks.
I intend to make the pattern-matching part of Lerp more
intuitive. I'll be using a beefed up version of last month's simple predicate
logic system. I will integrate it into the language in the same way perl uses
regular expression matching: you have some imperative code that goes along
statement by statement; then one of the statements happens to be written in a
declarative style, indicating a pattern-matching operation. The results of that
pattern-match are subsequently available as variables in the imperative code.
See Listing 1 for a simple example of such perl code.
The regular expression facilities in perl are responsible
for a significant chunk of perl's power. It's my hope that the predicate logic
system can play a similar role in Lerp. Instead of pattern-matching on strings,
I want to match patterns about facts in the game world.
Listing 1
A simple line of perl that extracts the hours,
minutes, and seconds. The input is a variable called
time,
which is expected to contain a string formatted “HH:MM:SS” (where each of
H, M, and S are digits). The =~ is a pattern matching operator, and the
sequence to the right of it is a declarative description of how the string
should be parsed.
($hours, $minutes, $seconds) = ($time =~ /(\d\d):(\d\d):(\d\d)/);
|
Integrating Pattern Matching
I want the pattern matching to integrate seamlessly into
the language design. I decided early on that a pattern-match operation would
return a data structure that could then be iterated through, and made it a goal
for the language to possess powerful iteration capabilities.
Recall that last month I used parentheses and unquoted
identifiers in order to designate a query, like this: (sister ?x ?y). This query
was then matched against a database of facts, or of inference rules that were
used to create facts.
Last month's syntax was in keeping with a tradition for
implementing simple predicate logic interpreters in Lisp-like languages. But
now that I want to embed pieces of predicate logic in an imperative language, I
find that I would rather use parentheses for the traditional role of grouping
imperative expressions, and I'd like unquoted identifiers to indicate imperative
variables (I am not a big fan of the dollar signs that are flying all over the
place in perl). So I adopted a new syntax where a query uses square brackets,
and predicate identifiers use a single quote, like this: ['sister ?x ?y].
I could set up the language to use one global database to
represent "the game world" but it seemed best to provide the ability to
instantiate arbitrary databases. I will treat these databases conceptually like
C++ classes, and I will borrow the dot operator "." to indicate a database
query. Finally, I provide the "each" keyword as a simple way of indicating an
iteration, with $_ being an implicit variable that gets assigned the value of
each iterated item, as in perl. A simple program to print out all the solutions
of ['sister ?x ?y] looks like Listing 2. It will print out some results that
look like this:
A solution is: [sister mark ann].
A solution is: [sister mark mary].
So far we can perform a query, but this doesn't seem very
integrated or powerful; the situation just doesn't have that perl magic to it
yet. As the return value of that query operation, I just got some tuples
back... if I want to dig inside the tuples, I will need to perform some
extraction operations. This would be a bit tedious, and it seems like the most
common usage case (for example, maybe I want to call a function, passing just
the values that match the query variable ?sis -- the people who are sisters of
someone.)
To make this situation nicer, I added some extra power to
the 'each' iterator. If the list argument to 'each' is a database query, the
parser inspects the query to find all the argument-matching slots (like ?x and
?sis in Listing 2). Then it defines local imperative variables, inside the body
of the iteration, for each of those slots. Now we're really in the neighborhood
of non-orthogonal language constructs. The results help make things concise and
easy to read; see Listing 3, which generates output like this:
ann is a sister of mark.
mary is a sister of mark.
It just feels nicer; we have some more power now.
|
Listing 2
proc show_sisters(Database db) {
results = db.['sister ?x ?sis];
each results {
print("A solution is: ", $_, ".\n");
}
}
|
|
Listing 3
each db.['sister ?x ?sis] {
print(sis, " is a sister of ", x, ".\n");
}
|
Further Features
Often we want to perform queries on a relation that is
supposed to be one-to-one or one-to-zero -- for example, the "carried_by"
relation (an entity can't be carried by two people, it can only be carried by
one, or nobody). In this case it would be cumbersome to perform an iteration,
or to get the query result back as a tuple, so I provide a special ?? variable
that means, "return the value of the item in this slot, not the whole tuple".
Thus we can say:
carried_by = db.['carrying ?? item];
and then the value of carried_by will be either the guy who
is carrying item, or a null-like value if nobody is. (If multiple
matches are found for ['carrying ?? item], an error is thrown.)
By giving an expression as the second argument of 'each',
instead of a code block, we can make a new list out of the query results, like
so:
results = each db.['sister mark ?sis] sis;
This makes a list containing each value of 'sis', much like
the Lisp function mapcar.
I also added the ability to “lift” an iteration up through
a function call. Assuming x is a variable containing a list, I can say
this:
f(each x);
and that is shorthand for:
each x f($_);
This is not a big gain so far, but it allows easy
expression of nested iterations. Suppose y and z are two more
lists, then
f(each x, each y, each z);
is shorthand for:
each x {
item_x = $_;
each y {
item_y = $_;
each z {
item_z = $_;
f(item_x, item_y, item_z);
}
}
}
except that in the shorthand version, it is assumed we
don't care about the order in which the iterations happen.
Unified Data Structures
I now have this generalized database mechanism, but I don’t
yet have basic language support for traditional data structures (lists, trees,
C++-style classes full of named slots, and the like). Rather than build those
data structures as separate language subsystems, I chose to unify data handling
within the language, and use the database model for everything. This helps to
ensure that we can leverage the expressive power of the pattern matching on all
of the frequently-used language constructs.
Hash table functionality – the ability to store values
indexed by arbitrary keys -- is already embodied by the semantics of the
database. Linked lists can be expressed within a database pretty simply, as can
arrays, so I won’t dwell on those. Once we have C++-style classes (coming in a
few paragraphs!), you could choose to build lists out of those as well.
In general, though, I doubt that structures like lists and
trees will be used very often in lerp. Usually when we implement these data
structures in other languages, we’re participating in a mentality of computation
scarcity. We use lists because appending to them is fast, or removing an object
out of the middle can be fast if the list is designed for it. Or we use trees
so that we can quickly maintain a sorted collection of objects, which remains
sorted as the collection is modified – and probably, we’re only maintaining a
sorted collection because we don’t want to re-sort all the objects when it’s
time to use them (since that would take CPU cycles!)
This CPU-scarcity attitude costs us a huge amount in terms
of software complexity. Whenever it’s possible to treat computation as
non-scarce, we can achieve much simpler, more powerful programs. These days,
that’s possible in an increasing number of contexts – because computers are so
fast, and large portions of our programs are not speed-sensitive. That’s the
area I’m aiming for with Lerp. If you want to try and engineer a Lerp program
to use minimal amounts of CPU, you can do that, but the language isn’t designed
to make it a primary concern.
struct Something
C++ gives us the ability to define classes with named
slots; I wanted a similar capability in lerp. I decided to use the C ‘struct’
keyword, and to implement classes as databases. A definition that looks like
this:
struct Something {
Integer x = 0;
Integer y = 1;
String z = "Hello, Sailor!";
};
turns into a database with the following entries:
[_member x Integer 0]
[_member y Integer 1]
[_member z String "Hello, Sailor!"]
You can use the dot operator to dereference struct members
as a lvalues or rvalues, and these are translated into the appropriate database
queries and assignments. For example, "thing.x" is equivalent to "thing.[_member
x ? ??]" (recall that the double-question-mark indicates that we wish to return
that slot as the value of this expression; the single question mark indicates a
value that we don't care about and wish to throw away, without even bothering to
name it.) Under this scheme, we get introspection naturally; to find out what
members are declared on a class, you can do this:
each thing.['_member
?name ?type ?value] { // Do something...
Conclusion, and Next Month
So far I have trotted out a bunch of language ideas. I'm
not doing this to convince you that this particular set of language semantics is
the greatest ever; rather, I want to provide lots of concrete examples of
diagonal language features for games, sewing the field for discussion. Perhaps
you think some of these features should work differently, or that some of them
be thrown out and replaced with entirely new ideas. That's good.
This month's sample code implements the features discussed
in this article, and more besides. You can play with the sample programs and
see how they go. Next month we'll look at some even crazier high-level features
(note that we haven’t done anything special to accommodate inference rules
yet!).
Figure 1
An illustration of straight-line interpolation versus
traveling along orthogonal vectors to get from A to B. e1 and
e2 are the basis vectors of the space. The green hypotenuse of
the triangle is the short path; the red sides of the triangle are the
Manhattan path.
|