Figure 1
The Inner Product,
November 2003
Jonathan Blow
(jon@number-none.com)
Last updated 12 January 2004
Piecewise Linear Data Models
Related articles:
Packing Integers
(May 2002)
Scalar Quantization (June 2002)
Transmitting Vectors (July 2002)
Arithmetic Coding,
Part 1 (August 2003)
Arithmetic Coding, Part 2 (September 2003)
Adaptive Compression Across Unreliable Networks (October 2003)
In a high-performance networked game, we want to compress our data to make efficient use of bandwidth. In previous articles I have discussed the use of an arithmetic coder for compression. Last month I showed how adaptive compression can be achieved in the face of unreliable communications (as when using UDP). However, these articles all assumed that the transmitted data would be built from sets of discrete symbols, like the alphabets used for text compression.
In a modern game, much of the data we're transmitting will not be alphabet-like. An alphabet has the property that neighboring symbols are distinct and largely unrelated. So if you are transmitting compressed text, and the next symbol is "R", that means it is not anything like "S". This influences the data structure design for these systems; to store symbol probabilities, we tend to use arrays, with a separate and independent probability value per symbol. This data structure design then influences the final algorithm design.
I used the alphabet paradigm in earlier articles for two reasons. Firstly, it helps to keep things simple; I was able to focus on the issues at hand, without juggling too many new concepts. Secondly, most of the arithmetic-coder-related information you'll find on the Internet assumes the data is built from alphabets; so there's an accord between those articles and other sources the interested reader might seek.
This month, I want to step away from that alphabet paradigm. In games we often manipulate values that are ideally continuous, or values where neighboring elements possess strong semantic similarities. In an earlier article I called these "coherent values"; some examples of coherent values are a game character's health or his position in the world. Sometimes these types of values have very high resolutions; building probability arrays for them, as one does with alphabets, would waste a lot of memory. We want a probability representation ("data model") that exploits the data's coherency. If we represent the data model as a smooth continuous function, we can use a piecewise linear approximation of that function as an efficient way to store and compute probabilities. Hence the title of this article, "Piecewise Linear Data Models".
Health
I'll now look more closely at the example of player health. I'll discuss this example in the context of a persistent-world online game, though the basic ideas apply to many types of games.
Suppose we store a player's health as a floating-point value between 0 and 1; 0 indicates that he's dead, 1 indicates that he's perfectly healthy. For the purposes of network transmission, we quantize this floating-point number into an integer at an arbitrary resolution (see "Packing Integers", May 2002). We could now transmit this integer directly, but we would be ignoring the fact that some health values are more likely than others; thus we would achieve poor compression.
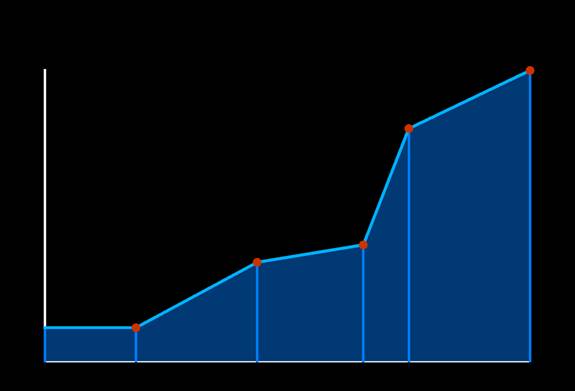
The best way to figure out your data probabilities is to measure them from actual gameplay; but since we're talking about a hypothetical game, let's speculate about health. Players want to feel safe, so if they have the ability to rest or be healed in some other way, they will do so when their health is low and they're not preoccupied (e.g. fighting). So if a player's health is low, it will likely not be low for very long. In fact, once a player's health falls below a certain point, chances are he's in an overly difficult combat session and may be killed soon; thus we have what statisticians call a "survivorship bias" that drives the average health value even higher. (Assume that players who are killed will lay on the ground for a short period of time, then be reincarnated in a far-away safe area). Given this, we may expect the function for health values to look like Figure 1. This figure depicts a piecewise linear approximation; the function is divided into a small number of segments, and the value of the function is determined by linearly interpolating the control points. Control points are defined at segment boundaries.
|
|
|
Figure 1 |
Recall that, to pack a number into an arithmetic coder, we need to define an interval of [0, 1], which means we need two things, the interval's size and its starting point. The interval size corresponds directly to the probability of the value we are packing. The starting point tells us which actual value it is; essentially it's just the ending point of the previous interval. (See "Using an Arithmetic Coder", parts 1 and 2, August - September 2003).
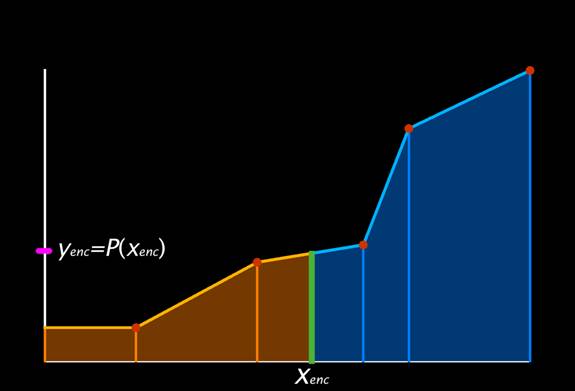
Given a piecewise linear function like Figure 1, the appropriate interval width is just the function's y value at the desired x coordinate, divided by the total area covered by the function graph. (Dividing by the area just normalizes the values to make sense in [0, 1]). The interval's starting point is just the total area of the function to the left of that x coordinate, divided by the area of the entire function. See Figure 2.
 |
|
|
Figure 2 |
How the Encoding Math Works
So that we can successfully decode our data, the math used to encode must be precise and reversible. Thus we store our piecewise function in integer coordinates and perform our area computations using only integer arithmetic.
Our piecewise function is defined as a collection of segments, and each of these segments is a right trapezoid. The main thing we need is a function for finding the area of such a trapezoid. I derived this by treating the right trapezoid as a rectangle with a triangle on top, finding the area of each, and summing them. Then I looked at mathworld.com and saw that they have a diagram and area derivation for a right trapezoid (see the References).
The area of the entire trapezoid is Area(x) = 1/2 Δx (y0 + y1). However, what we really want is the area of a piece of this trapezoid. In Figure 3b, we let x0 = 0 to simplify the math, and we find Area(x), where x is between 0 and Δx. After a little bit of algebraic substitution, we find that Area(x) = y0x + 1/2 Δy/Δx x2. This result will often not be an integer, but that is not really important, if we minimize the rounding and compute this function consistently so that rounding happens the same way. To minimize the rounding, we group the terms like this: Area(x) = y0x + (Δy x2) / (2Δx). Now there is only one divide operation, and it happens as late as possible, and it does not become magnified by any subsequent multiplications. Thus the rounding error will always be less than 1.
Earlier I said that the width of a coding interval was determined by its y value in the piecewise linear function. Ideally that's true, but in order to make the interval sizes always fit perfectly together, and to be consistent with rounding, it is best to define the interval width in terms of the trapezoid area function. So, the width of the interval for x is Area(x+1) - Area(x).
By letting x_0 = 0, we have been computing the area of each trapezoid in isolation. But it's easy to iterate over all the trapezoids at preprocess time and find their areas. Then we store an integer value with each trapezoid, telling us the area of all previous trapezoids in the function. We add that value to the Area(x) computed above.
The only remaining task is to find the correct trapezoid for a given x. In this month's sample code I implemented a simple-as-possible solution, where I just iterate over the trapezoids from left to right until I find the one that spans x. This is fine if you assume that your functions aren't built from too many trapezoids. If you need more speed, you can always binary search or use a caching scheme.
How to Decode This
When decoding the message, the arithmetic decoder will yield a point inside [0, 1]; once we convert this to an Area value, we need to figure out which function segment that lands in, i.e. map it through the inverse of our piecewise linear function to find x. The area we get from the decoder will be somewhere between Area(x) and Area(x+1). A simplistic but slow way to decode it is to iterate over all values of x, computing Area(x) and Area(x+1) until we get results that straddle the area value. (Hey, it's not pretty, but it was the first thing I implemented and it worked the first time. Don't underestimate the value of simplicity when you are initially getting a system running).
For a more elegant solution, we note that the x values are consecutive integers; since the area value is always less than Area(x+1), if we compute the inverse area function carefully, we can ensure that the result is rounded downward to exactly x. We want to invert Area(x) = y0 x + Δy x2 / (2Δx), and one way to do that is by applying the quadratic formula. The quadratic formula contains an annoying plus-or-minus, but we can discard the minus since it represents a solution we're not interested in (outside the left-hand edge of the trapezoid). Let A represent the approximate area of the trapezoid that we get from the decoder. Then x = -y0 + (y02 + 2Δy/Δx A)1/2 Δx/Δy.
For our answer to be correct, we need to manipulate this equation to minimize rounding once again. That square root operation is obviously going to be a source of rounding, which is then exacerbated due to the multiplication by Δx. To fix this we factor the Δx into the square root (valid since Δx > 0) to yield: x = -y0 + (y02 Δx2 + 2 ΔxΔy A)1/2 / Δy. Now there are two sources of round-off, the square root and the divide, but they compound directly and the error will always be less than 1, which means we always produce the correct x.
Since we're dividing by Δy, this function is undefined when Δy = 0, which is a totally reasonable input case. But then, we can just go back to the area function and write it as Area(x) = y0 x, and thus at decode time, x = A/y0. Now, this new function is undefined when y0 = 0. But that should never happen, since that means the trapezoid has 0 area, so the values in that region have probability 0. If they have probability 0, it's not possible to transmit them in the first place (you should use an escape sequence at times like that, as we did in the earlier articles). We don't want to trust network input though, so if we encounter this case, we want to catch it and perhaps reject the entire message (since this is a sign that someone is screwing with us).
So far I have said that A is the area value gotten from the arithmetic decoder, but I have glossed over the actual computation of A. Let B = ((code - low) / range) * A0. The ((code - low) / range) gives you a value in [0, 1] corresponding to the remainder of the message; let A0 be the area of the entire function. Since we want to use integer math, we refactor the terms to perform the multiply before the divide: B = ((code - low) * A0) / range. So B is the amount of area from the left-hand side of the function up to x. We find the segment of the function that contains B, then we say A = B - Aprev, where Aprev is the sum of all the previous trapezoids' areas. Now A tells us how much area in the current trapezoid is used by the message, and we apply the quadratic formula from there. It may seem troublesome that here we are doing yet another divide, _before_ feeding this number into the earlier math, in a place where the A gets multiplied by some big factors. But in fact this doesn't matter. All we need for our math to yield the correct x is a value somewhere within the decoding interval for the current part of the message. Since this divide will bring the 'true' fractional value for A down to the next lowest integer, and intervals are always bounded on integers, this computation cannot bring us outside the interval. We are safe.
Sample Code
This month's sample code applies piecewise linear data models to player health and position; see Figure 4 for a position example. In order to accommodate the math from this article, some of the code uses 64-bit integer operations. There are some limits on the resolution of the domain and range of the piecewise function (necessary to avoid overflow), but these limits are high enough that they likely won't be a problem. For details, see the README packaged with the code.
References
"Trapezoid", Eric Weisstein’s World of Mathematics,
http://mathworld.com/Trapezoid.html